芯片制造商表示,亚马逊、谷歌和Meta等云巨头不想被锁定在Nvidia的InfiniBand中。他们希望一切都转移到标准以太网上。一段时间以来,计算机网络领域的专家一直在谈论第二个网络。通常的网络是将客户端计算机连接到服务器的网络,即LAN。人工智能的兴起在该网络“背后”创建了一个网络,一个“横向扩展”网络,用于运行AI任务,例如必须在数千个GPU上进行训练的深度学习程序。
这导致了开关芯片供应商Broadcom所说的严重僵局。Nvidia是运行深度学习的GPU芯片的主要供应商,它也正在成为互连芯片的网络技术的主要供应商,使用它在2020年收购Mellanox时添加的InfiniBand技术。
一些人认为,危险在于一切都与一家公司捆绑在一起,没有多元化,也没有办法建立一个由许多芯片竞争的数据中心。
“Nvidia正在做的是说,我可以以几千美元的价格出售一个GPU,或者我可以以50万到100万美元以上的价格出售相当于一个集成系统,”高级副总裁RamVelaga说。和网络芯片巨头Broadcom的核心交换组总经理,在接受ZDNet采访时。
Velaga告诉ZDNet:“这与云提供商的关系并不顺利,”意思是亚马逊和Alphabet的谷歌以及Meta和其他公司。这是因为这些云计算巨头的经济基础是在扩展计算资源时削减成本,这就要求避免单一采购。
“所以现在这个行业存在这种紧张局势,”他说。
为了解决这种紧张局势,Broadcom表示解决方案是遵循以太网技术的开放网络路径,远离InfiniBand的专有路径。
Broadcom周二推出了该公司最新的交换芯片Tomahawk5,能够在端点之间互连总计每秒51.2太比特的带宽。
“与我们进行了接触,说,嘿,看,如果以太网生态系统能够帮助解决InfiniBand能够为GPU互连带来的所有好处,并将其带入以太网等主流技术,那么它就可以普遍使用,并创建一个非常大的网络结构,它将帮助人们凭借GPU的优点而不是专有网络的优点取胜,”Velaga说。
Tomahawk5现已上市,紧随其后的是两年前Broadcom的前一部分Tomahawk4,后者是每秒25.6太比特的芯片。
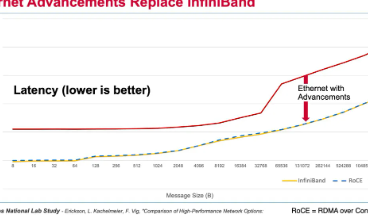
Tomahawk5部分旨在通过添加InfiniBand保留的功能来平衡竞争环境。关键区别在于延迟,即从A点发送第一位数据到B点的平均时间。延迟一直是InfiniBand的优势,这对于从GPU到内存再返回的过程变得尤为重要,为AI中的大型神经网络获取输入数据或获取参数数据。
一种称为RDMAoverConvergedEthernet或RoCE的新技术缩小了InfiniBand和以太网之间的延迟差距。借助RoCE,开放标准胜过NvidiaGPU和Infiniband的紧密耦合。
Velaga说:“一旦获得RoCE,就不再有无限带宽的优势了。”“以太网的性能实际上与InfiniBand的性能相当。”
“我们的论点是,如果我们能够执行InfiniBand,芯片到芯片,并且你有一个实际上正在寻找以太网成功的整个生态系统,你就有了用以太网取代infiniband的方法,并允许广泛的GPU生态系统成功,”Velaga说。
broadcom-ram-velaga-headshot-2022
Broadcom核心交换事业部总经理RamVelaga说,像亚马逊这样的云计算巨头“坚持认为GPU可以卖给他们的唯一方式是使用可以通过以太网传输的标准NIC接口”。
博通,2022年
提及广泛的GPU生态系统实际上是在暗指AI市场中提供新颖芯片架构的众多竞争硅供应商。
它们包括大量资金雄厚的初创公司,例如CerebrasSystems、Graphcore和SambaNova,但它们也包括云供应商自己的芯片,例如谷歌自己的TensorProcessingUnit或TPU,以及亚马逊的Trainium芯片。如果计算资源不依赖于Nvidia出售的单一网络,那么所有这些努力可能会有更多机会。
“今天的云计算巨头们说,我们想构建自己的GPU,但我们没有InfiniBand结构,”Velaga观察到。“如果你们能给我们一种等效于以太网的结构,我们就可以自己完成剩下的工作。”
Broadcom打赌,随着延迟问题的解决,InfiniBand的弱点将变得明显,例如该技术可以支持的GPU数量。“InfiniBand一直是一个有一定规模限制的系统,可能有1000个GPU,因为它并没有真正的分布式架构。”
此外,以太网交换机不仅可以服务于GPU,还可以服务于Intel和AMDCPU,因此将网络技术整合为一种方法具有一定的经济效益,Velaga建议。
Velaga说:“我预计这个市场最快的采用将来自GPU互连,并且在一段时间内,我可能预计平衡将是550,因为你将拥有可以使用的相同技术对于CPU互连和GPU互连,以及销售的CPU远多于GPU的事实,你将对数量进行标准化。”GPU将消耗大部分带宽,而CPU可能会消耗以太网交换机上的更多端口。
根据这一愿景,Velaga指出了AI处理的特殊能力,例如总共256个端口,每秒200千兆比特的以太网端口,是所有交换芯片中最多的。Broadcom声称这种密集的200-gig端口配置对于实现“平坦、低延迟的AI/ML集群”非常重要。
尽管Nvidia在数据中心领域有很大的影响力,今年数据中心GPU的销售额预计将达到160亿美元,但买家、云公司也有很大的影响力,而且优势在他们这一边。
“大云公司想要这个,”Velaga谈到从InfiniBand转向以太网时说。Velaga说:“当你拥有这些拥有强大购买力的庞大云时,他们已经表明他们有能力迫使供应商分解,这就是我们正在驾驭的势头。”“所有这些云确实不希望这样,他们坚持认为GPU可以卖给他们的唯一方法是使用可以通过以太网传输的标准NIC接口。
“这已经发生了:你看看亚马逊,他们就是这样购买的,看看Meta、谷歌,他们就是这样购买的。”
标签:
免责声明:本文由用户上传,如有侵权请联系删除!